NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning

NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). These models still struggle to judge where objects are, how they relate, and how they move in 3D.
SpatialClaw does not retrain the model. Instead, it changes the action interface the agent uses to call perception tools. The research team argues the interface is the bottleneck. Their solution is to treat code as the action interface. Across 20 benchmarks, SpatialClaw reaches 59.9% average accuracy. It outperforms the recent spatial agent SpaceTools by 11.2 points.
What is SpatialClaw
SpatialClaw is an agent loop wrapped around a stateful Python kernel. The kernel is pre-loaded with input frames and a set of primitives. Perception tools are plain Python callables. Their outputs, including masks, depth maps, camera geometry, and trajectories, are ordinary Python variables.
The kernel exposes six public entry points. InputImages holds the sampled frames. Metadata carries frame rate, duration, and frame indices. tools exposes perception and geometry primitives. show() embeds an image into the agent’s next context. vlm dispatches queries to a separate VLM session. ReturnAnswer() submits the final answer.

Two perception tools are central. tools.Reconstruct wraps Depth Anything 3 and returns per-frame depth, camera intrinsics, extrinsics, and dense point maps. tools.SAM3 wraps SAM 3 and produces image or video masks from text, point, or box prompts. The framework adds lightweight utilities: tools.Geometry, tools.Mask, tools.Time, tools.Graph, and tools.Draw.
It is training-free. The same system prompt, tool set, and hyperparameters run across every benchmark and backbone.
Why the Action Interface Matters
The research team studied three action interfaces on the same question. Consider measuring the closest distance between a heater and a door.
Single-pass code writes one complete program and runs it once. It commits to a full strategy before seeing any intermediate mask or depth map. A wrong assumption then propagates straight to the answer.
Structured tool-call invokes named tools through a fixed JSON schema. It cannot freely combine outputs with NumPy or SciPy to express test-time computations. The closest-point operation has no pre-registered tool, so the result is wrong.
SpatialClaw composes tools in code, inspects results, then revises. It first computes a centroid distance, then notices the centroid uses a median. The agent switches to scipy.spatial.KDTree to find the true closest point. It submits 0.9439 m against a 0.9 m ground truth.
Benchmark
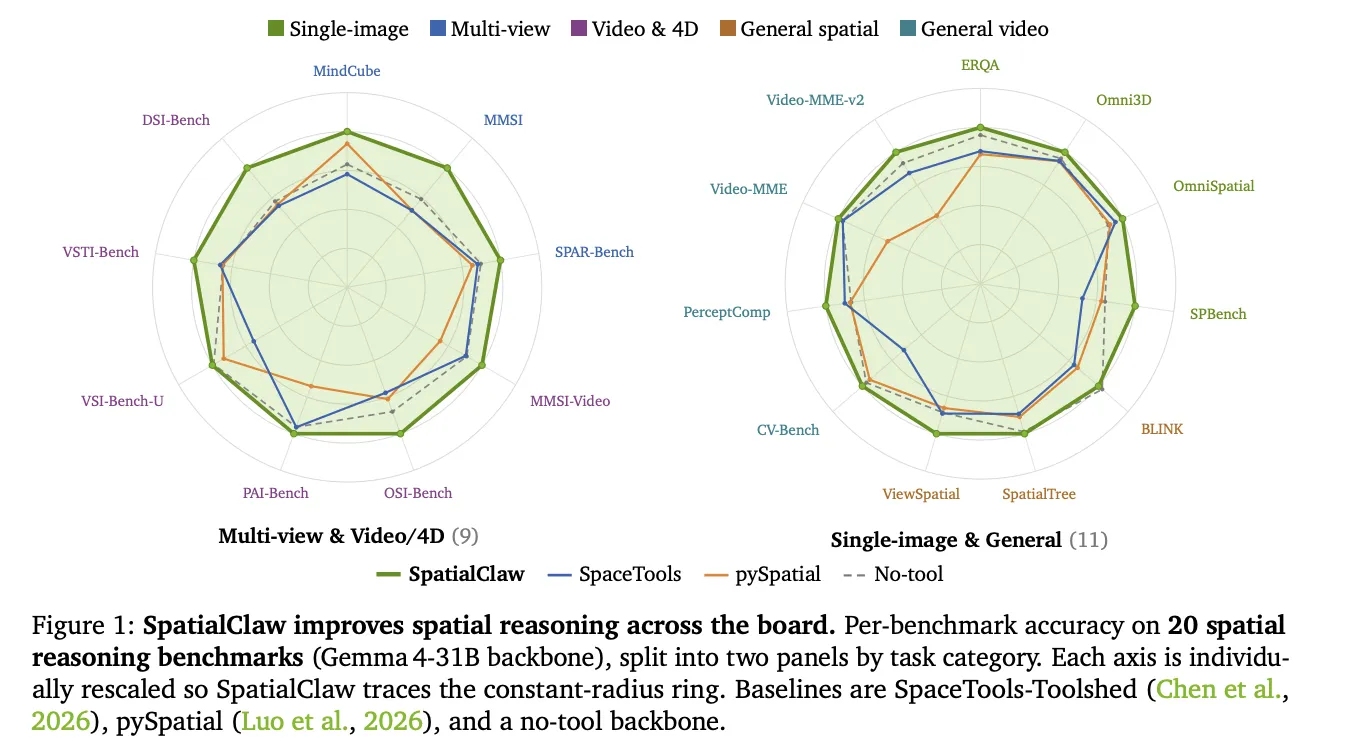
SpatialClaw was tested on 20 benchmarks across five categories. These span single-image, multi-view, general, video and 4D, and general video understanding. It improves over the no-tool baseline on all six backbones tested. Backbones range from 26B to 397B parameters across the Qwen3.5/3.6 and Gemma4 families.
A controlled comparison isolates the interface. All three variants share the same toolset and prompt. Only the action interface differs.
Gemma4-31B backbone, 20-benchmark average.
Against prior spatial agents on the same Gemma4-31B backbone, the gap widens.
The largest gains land on dynamic tasks. On Gemma4-31B, DSI-Bench rose +17.6 points and MindCube rose +15.3 points. These categories need chained geometric computation across frames and viewpoints.
An LLM-as-judge attribution explains the wins over structured tool-call. Code composition accounts for 52.2% of them. Control flow accounts for 19.5%, and the remaining 28.3% are interface-neutral.
Inside the Five-Stage Loop
Each sample runs a five-stage loop: planning, code generation, code execution, feedback assembly, and answer submission. A planner drafts a strategy without seeing the images. The main agent then writes one Python cell per step. A static AST checker rejects unsafe code before execution. The loop repeats until ReturnAnswer() is called or 30 steps pass.
The official repo runs on a LangGraph workflow and a persistent Jupyter kernel. Backbones serve through vLLM. Perception runs behind a FastAPI GPU service. A single quickstart runs one benchmark on one machine:
cd SpatialClaw
bash spatial_agent/scripts/setup.sh
cp .env.example .env # add API keys, or self-host vLLM
python -m spatial_agent.entrypoints.run \
–dataset spatial_agent/config/dataset/erqa.json \
–model spatial_agent/config/model/gemini-3-pro.json \
–concurrency 4
A representative agent cell composes perception with geometry, then revises:
recon = tools.Reconstruct.Reconstruct(InputImages)
seg = tools.SAM3.segment_video_by_text([“radiator heater”, “door”])
show(seg.visualize(1)) # inspect the masks first
# Closest-point distance via KD-tree, not centroids
pts_h = seg.get_masked_points(recon, frame=1, object=0) # object 0 = heater
pts_d = seg.get_masked_points(recon, frame=2, object=1) # object 1 = door
dists, _ = scipy.spatial.KDTree(pts_d).query(pts_h, k=1)
ReturnAnswer(float(dists.min()))
The agent picks primitives from the question itself. Distance questions invoke KD-tree search and vector norms. Direction questions rely on dot products. No category-specific routing was applied.
Use Cases
The design fits problems that need step-by-step geometric reasoning. Concrete examples include:
Robotics and embodied agents that measure metric distances between objects before acting.
Multi-view inspection, where an object’s facing direction is recovered from several camera angles.
Video and 4D analysis that tracks object or camera motion across frames.
Indoor scene question answering, such as “where is the door relative to the sink?”
Because it is training-free, teams can extend a deployed VLM without new data or fine-tuning.
Interactive Explainer
Key Takeaways
Code as the action interface: SpatialClaw lets a VLM write one Python cell per step into a persistent kernel, composing and revising perception outputs instead of committing to a fixed plan.
State of the art, training-free: 59.9% average across 20 spatial benchmarks, +11.2 points over the prior agent SpaceTools, with no benchmark- or model-specific tuning.
The interface is the lever: swapping only the action interface on Gemma4-31B moves accuracy from 56.7 (structured tool-call) to 59.9, and 52.2% of wins trace to code composition.
Biggest gains where geometry chains: dynamic 4D and multi-view tasks lead the lifts (DSI-Bench +17.6, MindCube +15.3), where steps must compose across frames and viewpoints.
Perception is the ceiling: gains transfer across six backbones (26B–397B), but the remaining bottleneck is perception quality, and the license is non-commercial.
Check out the Paper, Project and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us